To Continue Our Robot Story

2016.06.02
 (7 votes, average: 5.00 out of 5)
(7 votes, average: 5.00 out of 5)You have already known that robots.txt file can increase the online profit of your website by promoting it in the search engines. If you are eager to monetize your website, you should know how to create the robots.txt file. This file allows to forbid the indexation of unnecessary pages and to specify the sitemap.
Robots.txt sitemap
Directive “Sitemap” is used to detect sitemap.xml location in the robots.txt file.
The example of the robots.txt with sitemap.xml:

The sitemap.xml pointing through the Sitemap in your robots.txt. That directive allows the crawler to learn about the presence of a sitemap and start indexing it.
Directive Clean-Param
“Clean-param” Directive allows excluding from indexing pages with dynamic parameters. These pages can give the same content with a different URL of the page. Simply put, if the page is available in several locations. Our task is to remove all the extra dynamic addresses, which can be a million. To do this, we eliminate all dynamic parameters using a robots.txt directive “Clean-param”.
The “Clean-param” directive example:

Let’s Consider the example of the page with the following URL:

Robots.txt “Clean-param” example:

Or

Directive Crawl-delay
This instruction allows avoiding the server overload if the web crawlers are used to reach your site too often. This directive is relevant mainly for sites with a huge page size.
Robots.txt “Crawl-delay” example:

In this example, we “ask” Google robots to download the pages of our website no more than once per three seconds. Some search engines read the format with the fractional number, as a guideline parameter “Crawl-delay” robots.txt.
Comments in robots.txt file
The comments in the robots.txt begin with the hash sign # and are valid until the end of the current line and ignored by robots.
The examples of the comments in robots.txt file:

The Common Mistakes
1. The mistake in syntax:
![]()

2. The several directives “Disallow” in one line:
![]()

3. Wrong file name:
![]()

The live examples of robots.txt file profit
1. I have recently changed one of my robots.txt files pruning duplicate content pages to help to make higher quality and better-earning pages. In the process of doing that, I forgot that one of the most well pages on the site had a similar URL as the noisy pages.
About a week ago the site’s search traffic halved (right after Google was unable to crawl and index the powerful URL). I fixed the error pretty quickly, but the site now has hundreds of pages stuck in Google’s supplemental index, and I am out about $10,000 in profit for that one line of code! Both Google and Yahoo support wildcards, but you really have to be careful when changing the robots.txt file because a line like this:
Disallow: /*page
also blocks a file like this from being indexed in Google.
2. The use of a robots.txt file has long been debated among webmasters, as it can prove to be a strong tool when it is well written or one can shoot oneself in the foot with it. Unlike other SEO concepts that could be considered more abstract and for which we don’t have clear guidelines, the robots.txt file is completely documented by Google and other search engines.
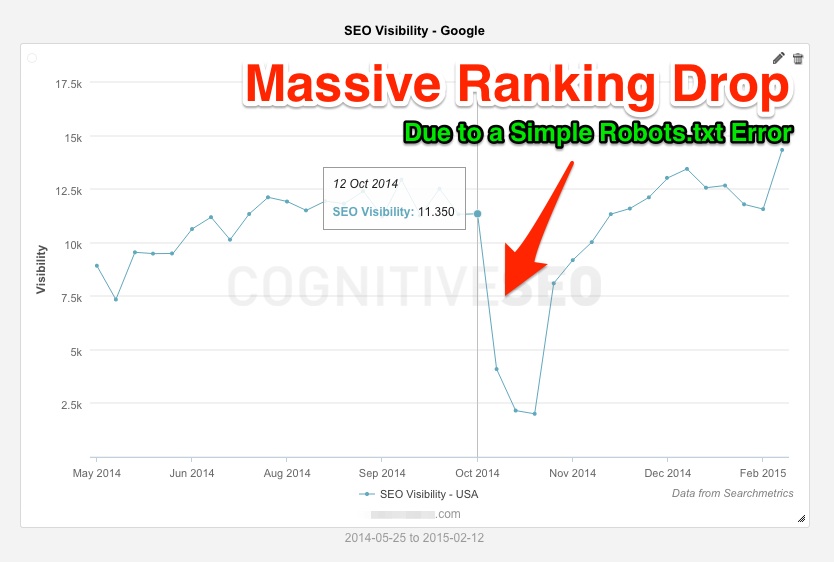
Razvan Gavrilas
* The feedback is taken from: http://cognitiveseo.com/blog/7052/critical-mistakes-in-your-robots-txt-will-break-your-rankings-and-you-wont-even-know-it/
Now, when you know everything about the robots.txt files, you can increase your online profit with ease.
But also, remember, that to monetize your website wisely you should also take into account some other important attributes. Such as:
How To Identify Search Engine Penalties
How To Get Indexed By Google Properly


