Make Friends With the Robot or How to Create the Robots.txt File

2016.06.02

 (6 votes, average: 4.83 out of 5)
(6 votes, average: 4.83 out of 5)What is the robots.txt file?
The robot.txt file is a text file which should be placed on the web server and tell the web crawlers rather to access a file or not.
What is the point?
The robot.txt is a very powerful file to expunge the indexing pages without quality content. For example, you have two versions of a page: the one for viewing in browsers and the other for printing. You had better the printing version expunged from crawling, or else you would risk to be imposed a duplicate content penalty.
Basic robots.txt examples:
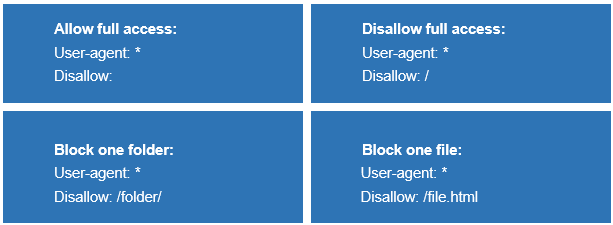
Note: to be applicable, the robots.txt should be placed in the top-level directory of a web server, i.e. https://yoursite.com/robots.txt
How to create a robots.txt file?
As long as a robots.txt file is just a text file, you can use the Notepad or any other plain text editor. You can also create it in the code editor or even “copy and paste” it.
Don’t focus on the idea that you are making a robots.txt file, just think that you are writing a simple note. They are pretty much the same process.
You can create the robots.txt file in two ways: manually and using online services.
Manually: As previously mentioned, you can create the robots.txt using any plain text editor. Create the content, depending on your requirements, and save it as a text file with the name of robots in txt format. It is simple as ABC. Creating the robots.txt file should not be a problem even for beginners.
Online: You can create the robots.txt file online and download it cut and dried. There is a great amount of online servers for robots.txt creation. It is up to you which one to use. But you have to be careful and check your file if it contains some forbidden information. Otherwise, the creation of the file robots.txt online can turn into a tragedy. To create the robots.txt this manner is not that safe, as manually. Because the file created manually reflects more accurately the structure of restriction.
How to set up a robots.txt file?
The proper robots.txt file configuration prevents the private information to be found by the search engines. However, we should not forget that the robots.txt commands are no more than a guide to action, and are not the protection. The robots of reliable search engines, like Google, follow the instructions in a robots.txt, but other robots can easily ignore them. To achieve the result, you have to understand and use robots.txt correctly.
The correct form of the robots.txt begins with the directive “User-agent” naming the robot that the certain directives are applied to.
For example:

Please note that this setting makes the robot use only the directive corresponding to user-agent’s name.
Here are the examples:

User-agent directive provides only the task to a particular robot. Right after the directive there are the tasks for the named robot. In the previous example, you can check up the usage of the prohibited directive “Disallow” that means “/*utm.” That is how we close the pages with UTM-marks.
The example of incorrect line in robots:

The example of correct line in robots:

As you can see in the example, the tasks in the robots.txt go in blocks. Every block considers the instruction for the certain robot or for all the robots “*”
Plus, it is very important to observe the right order of the tasks for robots.txt when you use both directives “Allow” and “Disallow”
“Allow” is the permission directive which is the opposite to the “Disallow” directive, the forbidden one.
The example of using the both directive:

This example forbids all the robots to index the pages beginning with “/blog”, and permits to index the pages beginning with“/blog/page”.
The same example in the right order:

At first, we forbid the whole part, and then we permit some of its parts.
Here is the other way to use both directives:

You can use the directives “Allow” and “Disallow” without switches, though it will be read opposite to the switch “/”.
The example of the directive without switches:

So, it is up to you how to create the right directive. Both variants are appropriate. Just be attentive and do not get confused.
Just put the right priorities and point the forbidden details in the switch of the directives.
Robots.txt syntax
The search engine robots execute the commands of the robots.txt. Every search engine can read the robots.txt syntax in its own way.
Check the set of the rules to prevent the common mistakes of the robots.txt:
- Every directive should begin from the new line.
- Don’t put more than one directive on the line.
- Don’t put the space in the very beginning of the line.
- The directive switch must be on one-line.
- Don’t put the directive switch in quotes.
- Don’t put a semicolon after the directive.
- The robot.txt command must be like: [Directive_name]:[optional space][value][optional space].
- The comments must be added after hash mark #.
- The empty line can be read as the finished directive User-agent.
- The directive “Disallow” (with a null value) is equal to “Allow: /” and means to allow everything.
- There is just one switch put in the directives “Allow” and “Disallow”.
- The uppercase letters are not allowed in the file name. For example, Robots.txt or ROBOTS.TXT are not correct.
- It is inappropriate to put the initial uppercase letters in the directive name. The robots.txt is not so case-sensitive, while the names of files and directories are very case-sensitive.
- In case the directive switch is the directory, put slash “/” before the directory name, i.e. Disallow: /category.
- Too heavy robots.txt (more than 32 Kb) are read as allowed and equal to “Disallow:”.
- Unavailable robots.txt can be read as allowed one.
- If the robots.txt is empty, it will be read as allowed one.
- Some listing directives “User-agent” without empty lines will be ignored, except the first one.
- Using the national characters is not allowed in robots.txt.
As far as different search engines can read the robots.txt syntax in their own way, some rules can be missed.
Try to put just necessary content to the robots.txt. Remember that brevity is everything. The fewer lines you have, the better result will be. And also attend your content quality.
Testing your robots.txt file
To check the correctness of the syntax and file structure, use one of the special online services. For example, Google proposes its own website analysis service: https://www.google.com/webmasters/tools/siteoverview?hl=ru
The robot that Google uses to index its search engine is called Googlebot. It understands a few more instructions than other robots.
To check the robots.txt file online, put the robot.txt to the root directory of the website. Otherwise, the server will not detect your robots.txt. It is recommended to check your robots.txt availability, i.e.: your_site.com/robots.txt.
There is a huge amount of online robots.txt validators. You can choose any.
Robots.txt Disallow
Disallow is the prohibitive directive that is frequently used in the file robots.txt. “Disallow” prohibits to index the website or some of its parts. It depends on the path given in the directive switch.
The example of forbidden website indexation:

This example closes the access for all robots to index the website.
The special symbols * and $ are allowed in the Disallow directory switch.
* – any quantity of any symbols. For example, the switch /page* suffices /page, /page1, /page-be-cool, /page/kak-skazat.
$ – points to the switch value correspondence. The directive Disallow will prohibit /page, but the website indexation /page1, /page-be-cool or /page/kak-skazat will be allowed.

If you close the website indexation, the search engines can react with “url restricted by robots.txt” error. If you need to prohibit the page indexation, you can use not just robots txt, but also the similar html-tags:
- meta name=»robots» content=»noindex»/> — not to index the page content;
- meta name=»robots» content=»nofollow»/> — not to follow the links;
- meta name=»robots» content=»none»/> — forbidden to index the page content and follow the links;
- meta name=»robots» content=»noindex, nofollow»/> — equal to content=»none».
Robots.txt Allow
Allow is opposite to Disallow. This directive has the similar syntax with “Disallow”.
The example of forbidden website indexation allowed some its parts:

It is forbidden to index the whole website, except the pages beginning with /page.
Allow and Disallow with empty value

Robots.txt file is one of the most important SEO tools, as it has a direct impact to your website indexation process. This tool is indispensable to interact with the web crawlers.
Make smart use of it and maximize your online profit.
To get more details review the second part of the article here.
How To Get Indexed By Search Engines Better:
How To Identify Search Engine Penalties.



